

Преобразование PDF в CSV с помощью Tabula
Действия и операция очень просты. Первый будет установить библиотеку Tabula в нашу среду разработки. Табула позволяет нам извлекать данные из таблиц в формате PDF в фреймы данных Pandas, библиотеку Python, оптимизированную для работы с CSV и массивами.
Это также позволяет извлекать и конвертировать между PDF, JSON, CSV и TSV. Драгоценный камень. Вы можете найти гораздо больше информации в репозиторий github
Устанавливаем Табула
При его выполнении мне выдала ошибку
решение, указанное в их документации, заключалось в том, чтобы удалить старую версию Tabula и установить новую.
Создаем исполняемый файл .py
Я создаю исполняемый файл .py, который я называю pdftocsv.py, и помещаю его в свою папку Downloads / eltiempo, и это файл со следующим кодом
PDF-файл для чтения называется inforatge.pdf, и я говорю ему, что вывод называется out.csv, и он останется в папке, в которой мы работаем.
Мы переходим в каталог, в котором находятся исполняемый файл и PDF-файл, который мы хотим преобразовать
Это важно, потому что если он скажет нам, что не может найти файл
В этом каталоге у нас есть PDF, файл .py, который мы создали, и там он вернет нужный нам CSV.
Выполняем код
Обратите внимание, что я использовал python, то есть я говорю ему запускать его с python 2, а не с python3, который не работает. И все, если он не возвращает ни одной ошибки, она у нас уже есть
Мы добавили в файл еще 3 строки для управления во время выполнения. в конце мы оставили наш файл pdftocsv.py как
Больше возможностей от Tabula
Еще примеры того, что мы можем сделать. Вариантов много, лучше всего пройти через официальный репозиторий Github, который я оставил
И, без сомнения, одна из самых полезных вещей для преобразования всех файлов PDF, JSON и т. Д. В каталоге.
Благодаря этому мы можем автоматизировать задачи, которые в противном случае были бы долгими и утомительными. В конце концов, это одна из причин использования этой библиотеки.
Реализация на Python
После того, как мы немного обсудили Tabula, давайте разберемся с ее реализацией на Python.
Установка библиотеки
Поскольку tabula-py – это библиотека Python с открытым исходным кодом, мы будем использовать установщик pip для установки библиотеки.
$ pip install tabula-py
Импорт библиотеки
После завершения установки мы можем проверить это, просто импортировав библиотеку, как показано ниже:
import tabula
Если программа выдает ошибку импорта, рекомендуется переустановить пакет.
Библиотека tabula-py предоставляет различные функции, такие как чтение файла PDF, чтение таблицы на определенной странице файла PDF, чтение нескольких таблиц на одной странице файла PDF или преобразование файлов PDF непосредственно в файл CSV.
Начнем с чтения PDF-файла.
Онлайн сервисы
В интернете можно воспользоваться услугами online конвертеров. Достаточно заглянуть в любой поисковик. Практически все они бесплатные. Кроме того, они очень просты в использовании. Для этого не нужен никакой самоучитель. С этой задачей справится любой «чайник».
Обратите внимание на то, что у всех сайтов свои возможности. Кроме того, результат выходного файла может отличаться очень сильно
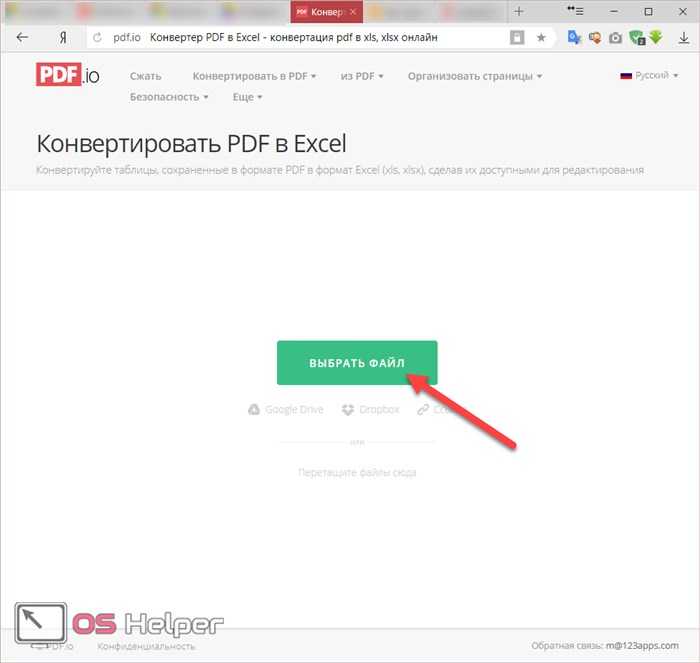
pdf.io
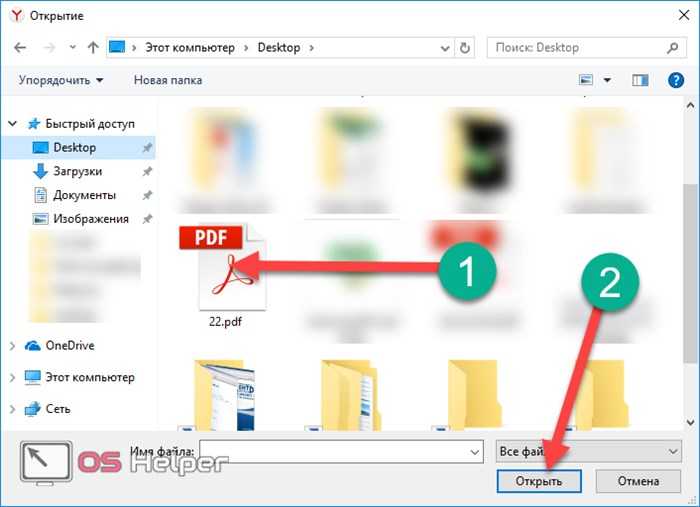
Главная страница выглядит просто. Но для того чтобы перевести таблицу в нужный формат, этого вполне достаточно. Для конвертации необходимо выполнить следующие действия:

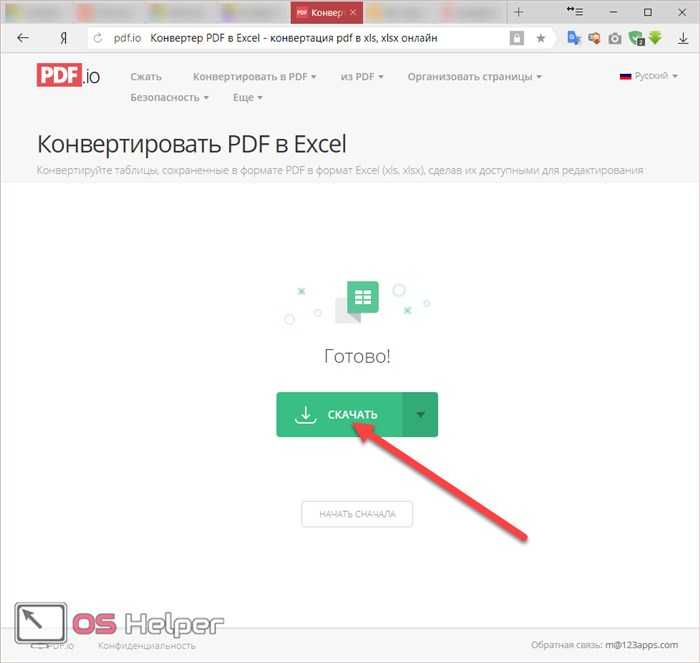


- Таблица выглядит вполне приемлемо. Но из-за старого формата около заголовка документа мы видим сообщение о том, что редактор работает в режиме совместимости. Более того, около формул появились значки «зеленого треугольника», а это первый сигнал возможных ошибок.
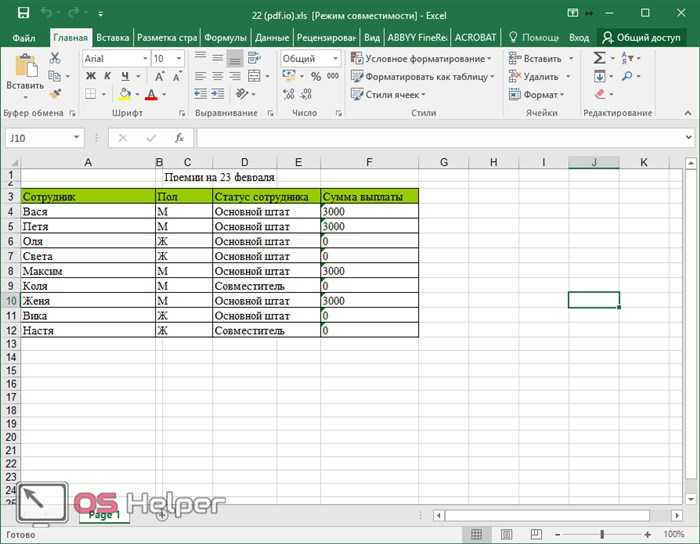
При желании данный файл можно загрузить на «Google Drive» или «Dropbox».

Кроме этого, стоит заметить, что существует альтернативный вариант добавления файла (практически на всех сайтах). Для этого нужно сделать клик левой кнопкой мыши и, не отпуская пальца, перетащить файл в окно браузера.

Результат будет точно таким же, как и при помощи кнопки «Обзор».
smallpdf.com
Данный портал более функциональный. Нам предлагают зарегистрироваться, чтобы воспользоваться дополнительными опциями. Более того, существует возможность скачать программу для offline конвертации.
Разумеется, нам стараются продемонстрировать различные функции, которых нет в обычной версии.
Покупать мы не будем. Переделать документ можно бесплатно при помощи сайта. Здесь принцип работы точно такой же.
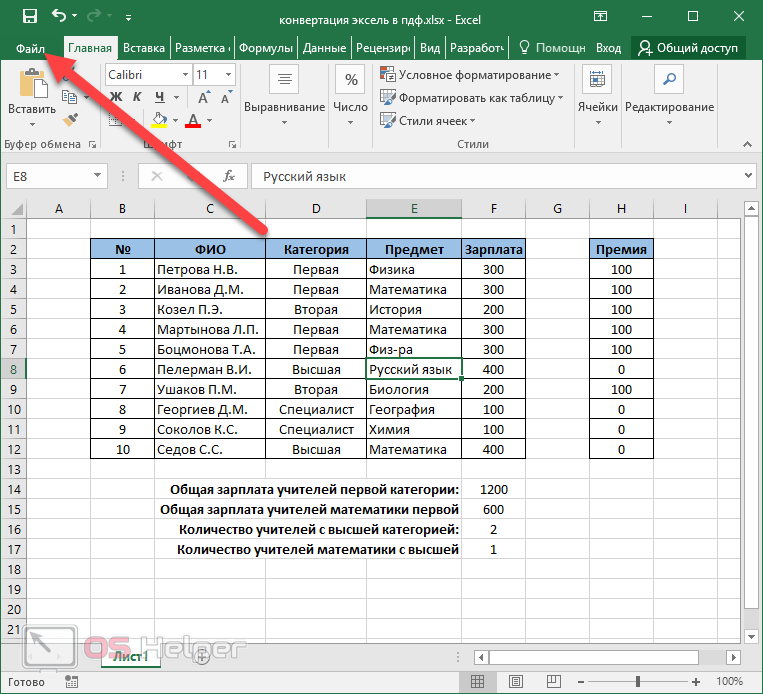
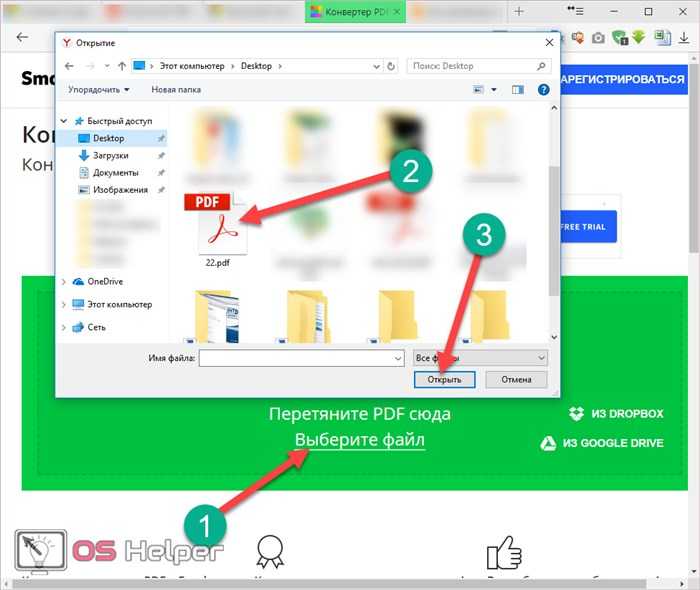
Кликните на иконку «стрелочки вниз». Далее вас попросят указать путь и имя
Обратите внимание на то, что здесь используется новый формат таблиц xlsx. На предыдущем сайте такой возможности не было
После этого нажмите на «Сохранить».

- Первым делом мы видим, что на листе указан только заголовок. Дело в том, что при конвертации было создано два листа. С одной стороны – это удобно, когда у вас несколько таблиц. Но когда одна – это большой минус.
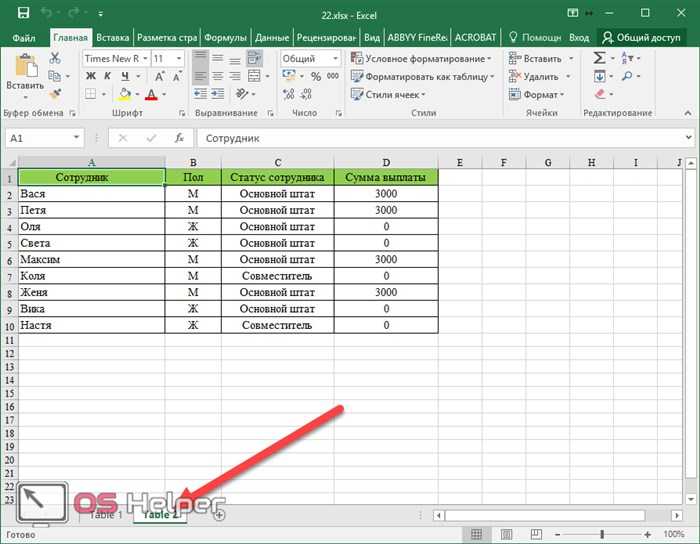
Теперь возможности редактирования доступны в полном объеме.
Как скопировать таблицу из PDF в Word
Когда вы пытаетесь переместить таблицу из PDF в Word, просто скопировав и вставив ее, все, что вы скопируете, — это значения. Форматирование таблицы будет потеряно в процессе.
Поскольку обычно вам необходимо скопировать всю таблицу, вам нужно будет найти другой метод, чтобы вставить строки и столбцы полностью. Эта статья покажет вам, как это сделать.
Откройте PDF с помощью Microsoft Word
Один из самых простых способов преобразования таблицы из PDF в документ Word — просто открыть PDF в Word. Это работает со всеми более новыми версиями Microsoft Word и занимает всего несколько шагов.
Для этого вам необходимо:
- Кликните документ PDF правой кнопкой мыши.
- Выберите «Открыть с помощью«.
- Выберите «Word (рабочий стол)«. Если его нет в раскрывающемся меню, выберите «Выбрать другое приложение», нажмите «Найти другое приложение на этом компьютере» и перейдите к своему EXE-файлу Microsoft Word.
- Открывается окно с сообщением «Word теперь преобразует ваш PDF-файл в редактируемый документ Word…»
- Нажмите «ОК«.
- Microsoft Word должен открыть PDF-документ.
Обратите внимание, что Microsoft Word преобразует полный PDF-документ. Поэтому, если вы хотите скопировать только таблицу в другой документ Word, вы можете:
- Выберите стол, кликнув значок «переместить» в верхнем левом углу (стрелки указывают в четырех направлениях).
- Кликните правой кнопкой мыши по таблице.
- Выберите «Копировать«.
- Откройте документ Word, в который вы хотите вставить таблицу.
- Кликните документ правой кнопкой мыши.
- Выберите «Вставить«.
- Таблица должна появиться.
Конвертируйте PDF в Word через Acrobat Reader
После установки программного обеспечения вы должны:
- Откройте документ PDF с помощью Adobe Acrobat.
- Кликните вкладку «Файл» в верхнем левом углу окна.
- Выберите вариант «Преобразовать в Word, Excel или PowerPoint».
- В новом окне нажмите синюю кнопку «Экспорт в Word».
Ваш PDF документ будет преобразован в документ Word. Затем вы можете использовать тот же метод, что и в предыдущем разделе, чтобы скопировать / вставить таблицу в документ Word, где должна быть ваша таблица.
Имейте в виду, что вам понадобится учетная запись Adobe, чтобы использовать эту опцию.
Использование стороннего приложения или веб-инструмента
Иногда самый быстрый способ скопировать содержимое PDF-документа в документ Word — это преобразовать его онлайн. В частности, это полезно, если вы работаете с облачными файлами вместо файлов на вашем диске.
Вы можете использовать расширение Google Chrome, например Небольшой PDFили онлайн веб-инструмент, такой как SimplyPDF, Все они работают по схожему принципу — выберите файл на своем диске или в облачном хранилище (например, Dropbox или OneDrive), а затем преобразуйте его в документ Word одним кликом мыши.
Затем вы можете просто скопировать таблицу из этого документа в другой.
Конвертировать легко
Как видите, скопировать таблицу из файла PDF в Microsoft Word довольно просто. Самое простое решение — открыть PDF-файл с помощью Word, который автоматически преобразует его для вас.
Вы также можете экспортировать его вручную в документ Word через Adobe Acrobat, и существует множество онлайн-инструментов, которые могут конвертировать документы за вас в несколько кликов.
Извлечение текста с помощью PyPDF2
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
И все! Система сама распознает текст и отправляет его в Word
Преобразование PDF в Word
- Загрузите PDF-файл.
- Выберите Word 2007-2013 (*.docx) или Word 2003 (*.doc) из выпадающего меню.
- Настройте дополнительные параметры.
- Нажмите «Начать».
Оставайтесь на связи:
- Закладка Нравится 86k поделиться 2k твитнуть
Лучший инструмент для преобразования PDF в Word
Всё просто. Загрузите PDF-документ с жёсткого диска / из облачного хранилища или перетащите в поле загрузки.
После загрузки PDF-файла выберите формат Microsoft Word из выпадающего меню. Доступно два варианта: DOC и DOCX.
После этого нажмите на «Сохранить изменения», а PDF-конвертер позаботится об остальном.
Онлайн-инструмент для преобразования PDF в Word
Вам не надо скачивать приложение или устанавливать программу. PDF2Go работает онлайн в любом браузере. Просто подключитесь к сети и зайдите на PDF2Go.com.
Забудьте о вредоносных программах и вирусах, просто скачайте полученный документ Word.
Зачем создавать Word из PDF-файла?
Несмотря на универсальность формата, PDF-документы сложно редактировать. Чтобы извлечь или отредактировать текст, надо преобразовать PDF в редактируемый Word.
![4 рабочих метода преобразования pdf в excel [таблица включена]](https://befam.ru/wp-content/uploads/8/1/c/81c855d083fdabe03db5242202e73cf6.png)
Оптическое распознавание символов (OCR) позволяет редактировать даже отсканированные книги. Не тратьте время, чтобы скопировать текст вручную, мы обо всём позаботимся!
Безопасное преобразование PDF в Word!
Если вы преобразуете PDF в документ Microsoft Word на сайте PDF2Go, вашему файлу ничего не угрожает.
SSL-шифрование, регулярная очистка сервера, безопасность загрузки и скачивания файлов. Все права на документы остаются за вами.
Для получения дополнительной информации ознакомьтесь с Политикой конфиденциальности.
В какой формат можно преобразовать?
Этот конвертер создан для преобразования PDF-файлов в документы Microsoft Word формата DOC и DOCX. Вы можете конвертировать PDF-файл и в другой текстовый документ!
Например:
ODT, RTF, TXT и другие
Мобильный конвертер PDF-файлов
Конвертируйте PDF-файлы на компьютере, смартфоне или планшете!
Онлайн-сервис PDF2Go позволяет конвертировать PDF-файлы в Word. В поезде или автобусе, в отпуске, на работе или дома — просто подключитесь к сети!
Чтобы оставить отзыв, преобразуйте и скачайте хотя бы один файл
Извлечь изображения из PDF-файла
Извлекает изображения из PDF-файла.
Входные параметры
| Аргумент | Необязательно | Принимает | Значение по умолчанию | Description |
|---|---|---|---|---|
| PDF file | Нет | PDF-файл, из которого требуется извлечь изображения. Введите путь к файлу, переменную, содержащую файл, или текстовый путь | ||
| Password | Да | Прямой ввод зашифрованного текста или | Пароль PDF-файла. Оставьте это поле пустым, если PDF-файл не защищен паролем | |
| Page(s) to extract | Н/Д | Все, Одна, Диапазон | Все | Указывает, со скольких страниц требуется извлечь изображения: все страницы, одна страница или диапазон страниц |
| Single page number | Нет | Номер одной страницы, с которой требуется извлечь изображения. | ||
| From page number | Нет | Номер первой страницы из диапазона страниц, из которого требуется извлечь изображения | ||
| To page number | Нет | Номер последней страницы из диапазона страниц, из которого требуется извлечь изображения | ||
| Image(s) name | Нет | Как начинаются имена изображений. Пример имен извлеченных изображений: GivenName_1, GivenName_2 | ||
| Save image(s) to | Нет | Папка для сохранения извлеченных изображений как PNG-файлов |
Исключения
| Исключение | Description |
|---|---|
| Недопустимый пароль | Данный пароль недопустим |
| Не удалось извлечь изображения | Указывает, что произошла ошибка при извлечении изображений из данных страниц PDF-файла |
| Папка не существует | Указывает, что папка не существует. |
| PDF-файл не существует | Файл не существует по данному пути |
Автокликер для 1С
Внешняя обработка, запускаемая в обычном (неуправляемом) режиме для автоматизации действий пользователя (кликер). ActiveX компонента, используемая в обработке, получает события от клавиатуры и мыши по всей области экрана в любом приложении и транслирует их в 1С, получает информацию о процессах, текущем активном приложении, выбранном языке в текущем приложении, умеет сохранять снимки произвольной области экрана, активных окон, буфера обмена, а также, в режиме воспроизведения умеет активировать описанные выше события. Все методы и свойства компоненты доступны при непосредственной интеграции в 1С. Примеры обращения к компоненте представлены в открытом коде обработки.
1 стартмани
03.04.2017
46442
87
slava_1c
67
74
Экспорт текста через pdf2txt.py
Инструмент командной строки pdf2txt.py, который идет вместе с PDFMiner может извлекать текст из файла PDF и выводить его на stdout по умолчанию. Он не будет распознавать текст из изображений, а PDFMiner не поддерживает оптическое распознавание символов. Давайте попробуем использовать простейший метод его использования, суть которого заключается в простой передаче пути к нашему PDF файлу. Мы используем наш w9.pdf Открываем терминал и ищем место, где вы сохранили этот файл, или обновляем указанную ниже команду, для наводки на этот файл:
Shell
pdf2txt.py w9.pdf
| 1 | pdf2txt.pyw9.pdf |
Если вы запустите это команду, она выведет весь текст в stdout. Вы также можете сделать так, чтобы pdf2txt.py записывал текст в файл в качестве текста, HTML или XML. Формат XML даст много информации о PDF файле, так как хранит в себе расположение каждой буквы в документе, а также информацию о шрифтах.
HTML не рекомендуется, так как разметка, генерируемая pdf2txt, скорее всего будет выглядеть не очень хорошо. Посмотрим, как получить выдачу в различных форматах:
Shell
pdf2txt.py -o w9.html w9.pdf
pdf2txt.py -o w9.xml w9.pdf
|
1 |
pdf2txt.py-ow9.htmlw9.pdf pdf2txt.py-ow9.xmlw9.pdf |
Первая команда создаст документ HTML, в то время как вторая создаст XML. Вот скриншот того, что я получил, воспользовавшись HTML конверсией:
Как вы видите, конец выглядит не лучшим образом, но бывало и хуже. Получаемый на выходе XML очень подробный, так что я не смогу выложить его здесь. Однако, есть сниппет, который даст вам понимание того, как это выглядит:
XHTML
<pages>
<page id=»1″ bbox=»0.000,0.000,611.976,791.968″ rotate=»0″>
<textbox id=»0″ bbox=»36.000,732.312,100.106,761.160″>
<textline bbox=»36.000,732.312,100.106,761.160″>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»36.000,736.334,40.018,744.496″ size=»8.162″>F</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»40.018,736.334,44.036,744.496″ size=»8.162″>o</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»44.036,736.334,46.367,744.496″ size=»8.162″>r</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»46.367,736.334,52.338,744.496″ size=»8.162″>m</text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»52.338,736.334,54.284,744.496″ size=»8.162″> </text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»54.284,736.334,56.230,744.496″ size=»8.162″> </text>
<text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»56.230,736.334,58.176,744.496″ size=»8.162″> </text
><text font=»JYMPLA+HelveticaNeueLTStd-Roman» bbox=»58.176,736.334,60.122,744.496″ size=»8.162″> </text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»60.122,732.312,78.794,761.160″ size=»28.848″>W</text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»78.794,732.312,87.626,761.160″ size=»28.848″>-</text>
<text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn» bbox=»87.626,732.312,100.106,761.160″ size=»28.848″>9</text>
<text></text>
</textline>
|
1 |
<pages> <page id=»1″bbox=»0.000,0.000,611.976,791.968″rotate=»0″> <textbox id=»0″bbox=»36.000,732.312,100.106,761.160″> <textline bbox=»36.000,732.312,100.106,761.160″> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»36.000,736.334,40.018,744.496″size=»8.162″>F</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»40.018,736.334,44.036,744.496″size=»8.162″>o</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»44.036,736.334,46.367,744.496″size=»8.162″>r</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»46.367,736.334,52.338,744.496″size=»8.162″>m</text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»52.338,736.334,54.284,744.496″size=»8.162″></text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»54.284,736.334,56.230,744.496″size=»8.162″></text> <text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»56.230,736.334,58.176,744.496″size=»8.162″></text ><text font=»JYMPLA+HelveticaNeueLTStd-Roman»bbox=»58.176,736.334,60.122,744.496″size=»8.162″></text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»60.122,732.312,78.794,761.160″size=»28.848″>W</text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»78.794,732.312,87.626,761.160″size=»28.848″>-</text> <text font=»ZWOHBU+HelveticaNeueLTStd-BlkCn»bbox=»87.626,732.312,100.106,761.160″size=»28.848″>9</text> <text></text> </textline> |
Навигатор по конфигурации базы 1С 8.3
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.95 от 07.05.2023
3 стартмани
28.10.2018
58929
530
ROL32
72
183
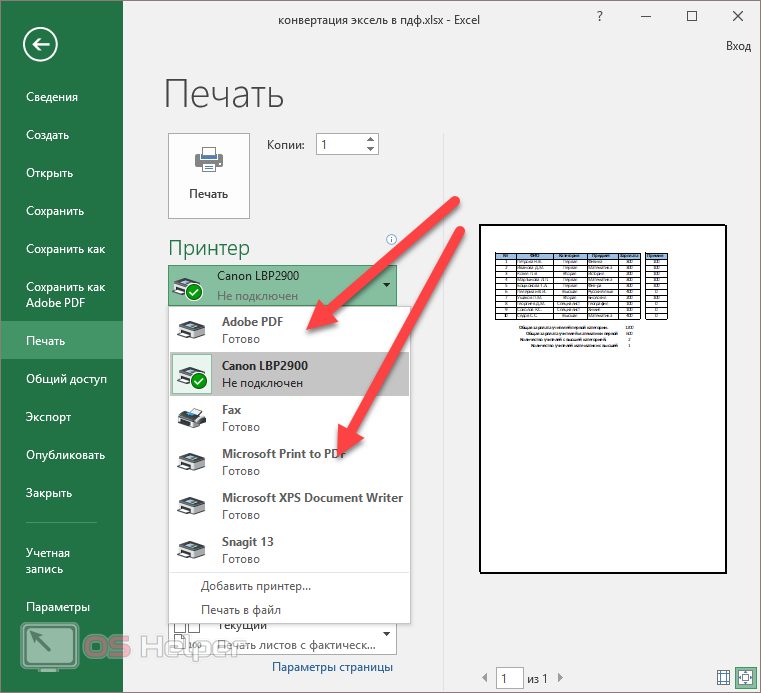
Как скопировать данные из PDF в Excel
Вот семь шагов для копирования данных из PDF в Excel:
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
1. Откройте PDF в Word
Начните с открытия файла PDF, содержащего данные, которые вы хотите скопировать. Есть два способа добиться этого. Сначала откройте проводник Windows и найдите PDF-файл. С помощью мыши щелкните файл правой кнопкой мыши, чтобы открыть раскрывающееся меню. Наведите курсор на опцию «Открыть с помощью», чтобы открыть другое меню. Выберите версию Microsoft Word, установленную на вашем компьютере. Например, вы можете выбрать Microsoft 2019.
Второй способ — открыть документ Word и перейти на вкладку «Файл». Выберите «Открыть», а затем «Обзор». Это представляет окно «Открыть». Найдите документ Word и нажмите «Открыть» в нижней части окна.
2. Преобразуйте документ и нажмите «Включить редактирование».
После того, как вы открыли PDF-файл в Word, появится окно, информирующее вас о том, что программа преобразует файл в документ. Он также говорит, что преобразование может занять некоторое время. Это зависит от размера файла и наличия в нем графики. Нажмите кнопку «ОК» для подтверждения. После преобразования файла PDF в документ Word может потребоваться включить функцию редактирования. Иногда Word открывает документ в режиме «Защищенный просмотр», что означает, что вы можете только просматривать файл. Найдите желтый баннер в верхней части страницы и нажмите кнопку «Включить редактирование».
3. Скопируйте данные из документа
После того, как вы включили функцию редактирования, теперь вы можете просматривать и редактировать исходный PDF-файл как документ Word. Найдите таблицу, график или данные, которые вы хотите скопировать в Excel. С помощью мыши щелкните данные и перетащите мышь, чтобы выделить всю таблицу. После того, как вы выделили информацию, скопируйте данные. Есть три способа сделать это. Сначала щелкните правой кнопкой мыши и выберите «Копировать» в раскрывающемся меню. Либо выберите параметр «Копировать» на вкладке «Главная» на панели инструментов. Наконец, вы можете использовать сочетание клавиш «Ctrl» и «C», чтобы скопировать данные.
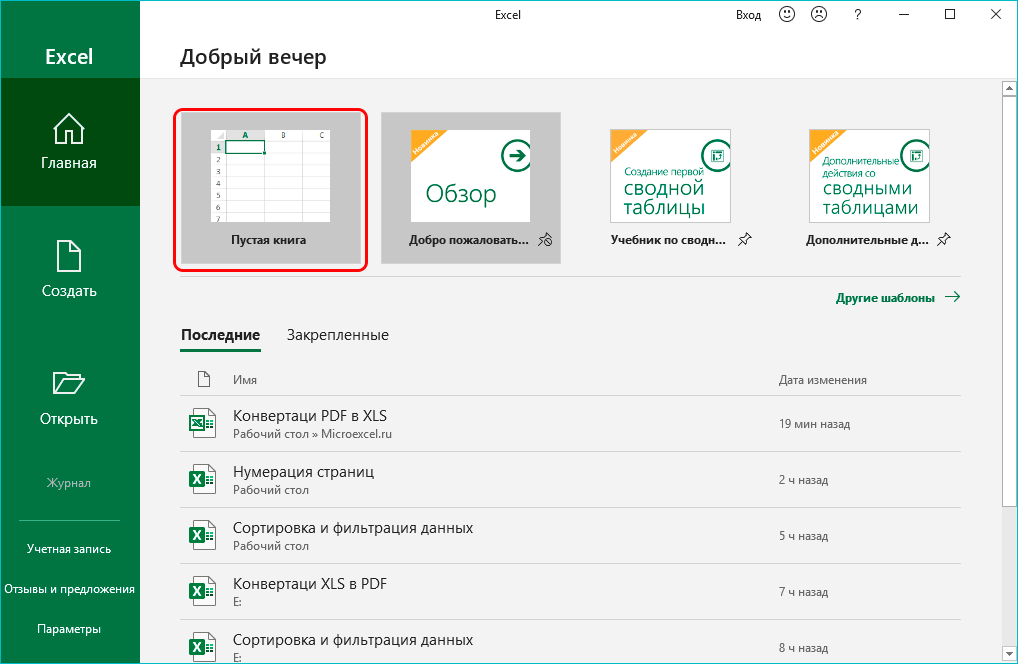
4. Откройте правильную электронную таблицу Excel
Далее запустите Microsoft Excel. Вы можете найти Excel, выполнив поиск в строке поиска Windows в нижней части экрана. После того, как вы запустили программу, откройте нужный файл. Выберите новую таблицу, нажав «Пустая книга» на вкладке «Создать». Если у вас уже есть подготовленный документ, то выберите вкладку «Открыть», а затем «Обзор». Найдите электронную таблицу в проводнике и дважды щелкните ее, чтобы открыть в Excel.
5. Вставьте данные в Excel
Открыв нужную электронную таблицу, вставьте данные в Excel. Есть три способа сделать это. Щелкните правой кнопкой мыши ячейку или область, куда вы хотите вставить информацию, и выберите параметр «Вставить» в раскрывающемся меню. Вы также можете нажать кнопку «Вставить» на вкладке «Главная» на панели инструментов. Последний способ — использовать сочетание клавиш «Ctrl» плюс «V». Если вы выбрали электронную таблицу с уже содержащимися данными, попробуйте вставить новую информацию в пустую область рабочей книги.
6. Отформатируйте информацию
После того, как вы вставили данные в Excel, вы можете отформатировать электронную таблицу. Иногда информационная таблица переносится корректно, то есть не требует правок. В других случаях некоторые значения или таблицы становятся неуместными. Когда это произойдет, вы можете отформатировать информацию, чтобы она была удобочитаемой и выровнена с остальными данными. В зависимости от того, что это за ошибка, вы можете использовать различные методы для ее исправления. Например, вам может потребоваться вставить или удалить строку или столбец. Вы можете сдвигать ячейки влево или вправо. Наконец, попробуйте объединить и разъединить ячейки, к которым вы можете получить доступ через вкладку «Главная».
7. Назовите и сохраните таблицу.
После того, как вы отформатировали информацию, дайте название и сохраните данные. Возможно, у вас уже есть заголовок, если вы открыли ранее начатую электронную таблицу. В этом случае вы можете нажать «Файл», а затем «Сохранить» или «Сохранить как», чтобы сохранить документ. Если вы создали новую электронную таблицу, Excel требует, чтобы вы назвали документ, прежде чем вы сможете его сохранить. Нажмите «Сохранить как» и введите название в текстовое поле «Введите имя файла здесь». Наконец, нажмите кнопку «Сохранить» справа от текстовых полей, чтобы сохранить электронную таблицу. Сохранение электронной таблицы подтверждает все внесенные вами изменения.
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
09.01.2019
76969
286
informa1555
246
207
Конвертировать PDF-данных в электронные таблицы Excel
Скинуть файлы здесь или же
Максимальный размер файла!
The file exceeds the maximum file size allowed. Please feel free to use our desktop version.
The file exceeds the maximum number of pages allowed. Please feel free to use our desktop version.
Максимальный размер файла!
- >
- Загрузка завершена В ожидании Загрузка не удалась Поврежденный файл Файл защищен Идёт конвертация Идёт сжатие PDF >>> Конвертирование завершено Конвертирование не удалось! Сжатие не удалось!
Подписывайся to enable batch conversion. to enable batch compression. If you have subscribed, you need to Вход.
- High Сжать больше, хуже качество
- Medium Сжать хороршо, хорошее качество
- Low Сжать меньше, лучшее качество
Как конвертировать PDF в Excel
Сначала перетащите файл в окно или просто нажмите кнопку «Выбрать файл», чтобы загрузить файл PDF. Затем наши серверы преобразуют ваш PDF в редактируемый Excel XLSX, и вам просто нужно будет его скачать.
Безопасность
Ваша конфиденциальность — наш приоритет. После конвертирования PDF в Excel мы всегда удаляем файлы с наших серверов через час. Ни один из ваших файлов или их содержимое не будут использоваться во второй раз.
Бесплатный конвертер PDF в Excel
Эта онлайн-служба абсолютно бесплатна. На самом деле нет ограничений на количество обрабатываемых файлов, и нет необходимости создавать учетную запись.
Мы поддерживаем кросс-платформу
Мы конвертируем PDF в Excel на всех платформах, независимо от того, какую систему ОС вы используете — Windows, Mac или Linux.
Другие инструменты
Конвертировать таблицы Excel в PDF
Легко конвертировать PDF в Word
Конвертировать PDF-данных в электронные таблицы Excel
Конвертировать PDF-файла в набор оптимизированных изображений в формате PNG
Самый простой способ сжать размер вашего файла PDF
Accelerate your document workflows like never before
Чтение файла PDF
Библиотека tabula-py позволяет пользователям читать PDF-файл с помощью функции, известной как read_pdf().
Синтаксис:
obj = tabula.read_pdf(filename, args[])
Параметры:
filename: Параметр filename – это имя файла pdf, данные которого мы хотели бы прочитать.
Давайте преобразуем следующую таблицу данных pdf в фрейм данных pandas.
Имя файла: Marksheet_table.py
| Имя | Английский | Физика | Химия | Биология | Итог |
|---|---|---|---|---|---|
| А | 86 | 54 | 65 | 83 | 288 |
| B | 56 | 45 | 80 | 55 | 236 |
| C | 34 | 66 | 73 | 90 | 263 |
| D | 77 | 75 | 46 | 34 | 232 |
| E | 74 | 82 | 55 | 77 | 288 |
| F | 69 | 76 | 82 | 46 | 273 |
| G | 53 | 33 | 29 | 45 | 160 |
| H | 70 | 41 | 67 | 23 | 201 |
| I | 80 | 43 | 88 | 28 | 239 |
| J | 90 | 37 | 45 | 71 | 243 |
| K | 98 | 55 | 88 | 81 | 322 |
| L | 90 | 54 | 67 | 37 | 248 |
| M | 87 | 76 | 88 | 54 | 305 |
| N | 86 | 69 | 82 | 66 | 303 |
| О | 67 | 74 | 54 | 65 | 260 |
| P | 75 | 96 | 53 | 67 | 291 |
| Q | 45 | 87 | 80 | 45 | 257 |
| R | 44 | 66 | 49 | 78 | 237 |
| S | 78 | 39 | 78 | 80 | 275 |
| Т | 56 | 54 | 76 | 86 | 273 |
| U | 43 | 90 | 64 | 77 | 274 |
| V | 95 | 88 | 66 | 55 | 304 |
| W | 64 | 67 | 86 | 80 | 297 |
| X | 82 | 56 | 45 | 65 | 248 |
| Y | 79 | 65 | 70 | 54 | 268 |
| Z | 83 | 54 | 40 | 75 | 252 |
Вот пример, приведенный ниже, который демонстрирует, как извлечь данные из PDF.
Пример:
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 1) # printing the table print(mytable)
Выход:
Name English Physics Chemistry Biology Total 0 A 86 54 65 83 288 1 B 56 45 80 55 236 2 C 34 66 73 90 263 3 D 77 75 46 34 232 4 E 74 82 55 77 288 5 F 69 76 82 46 273 6 G 53 33 29 45 160 7 H 70 41 67 23 201 8 I 80 43 88 28 239 9 J 90 37 45 71 243 10 K 98 55 88 81 322 11 L 90 54 67 37 248 12 M 87 76 88 54 305 13 N 86 69 82 66 303 14 O 67 74 54 65 260 15 P 75 96 53 67 291 16 Q 45 87 80 45 257 17 R 44 66 49 78 237 18 S 78 39 78 80 275 19 T 56 54 77 86 273 20 U 43 90 64 77 274 21 V 95 88 66 55 304 22 W 64 67 86 80 297 23 X 82 56 45 65 248 24 Y 79 65 70 54 268 25 Z 83 54 40 75 252
Объяснение:
В приведенном выше примере мы импортировали необходимую библиотеку и определили переменную, в которой хранится адрес файла данных pdf. Затем мы использовали функцию read_pdf(), чтобы прочитать данные из PDF и распечатать их для пользователей. В результате таблица данных была успешно прочитана.


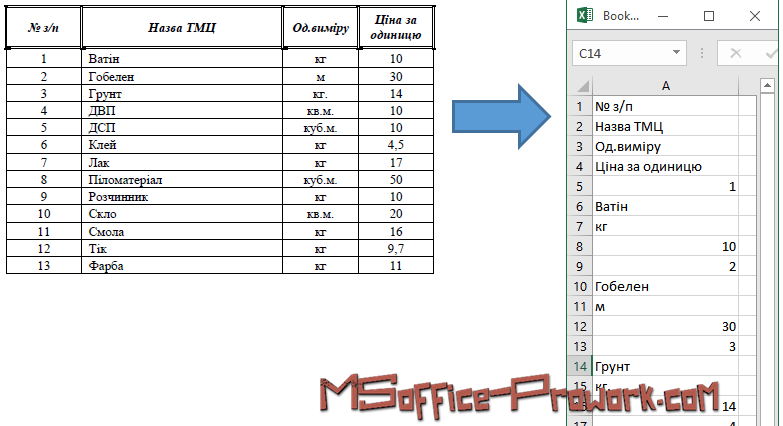


Примечание. Мы использовали параметр pages в функции read_pdf() для чтения данных с указанных страниц.
Давайте рассмотрим другой пример печати таблиц с определенной страницы, скажем, страницы номер 2.
Пример:
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 2) # printing the table print(mytable)
Выход:
Name Final Scores 0 A 288 1 B 236 2 C 263 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 16 Q 257 17 R 237 18 S 275 19 T 273 20 U 274 21 V 304 22 W 297 23 X 248 24 Y 268 25 Z 252
Объяснение:
В приведенном выше примере мы выполнили ту же процедуру, что и ранее. Однако мы присвоили параметру страниц значение 2 и распечатали первую таблицу указанной страницы. В результате таблица нулевого индекса на странице 2 была успешно напечатана.
Теперь давайте разберемся, что происходит, когда на одной странице файла данных PDF находится более одной таблицы.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку. Требуется время, чтобы понять, что к чему и какие проекты постоянно поддерживаются. Наше исследование позволило отобрать тех кандидатов, которые соответствуют современным требованиям:
- — библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
- — позиционируется как «быстрая и удобная библиотека чистого PDF» и реализована как оболочка для PDFMiner, и . Основная идея заключается в том, чтобы «надежно извлекать данные из наборов PDF‑файлов, используя как можно меньше кода».
- — расширение библиотеки , которое позволяет анализировать и конвертировать PDF‑документы. Не следует его путать с с таким же именем.
- — амбициозная промышленная библиотека, в основном ориентированная на оздание высококачественных PDF‑документов. Доступны как свободная версия с открытым исходным кодом, так и коммерческая, улучшенная, версия ReportLab PLUS.
- — чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF‑файлов в новых PDF‑файлах, созданных с помощью ReportLab.
В своём исследовании мы учитывали мнения Github-сообщества, а именно:
- Звёзды Github: общее количество звезд проекта, выставленных пользователям.
- Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
- Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
| Библиотека | Использование | Github | ReleasesGithub | Github |
|---|---|---|---|---|
| Чтение | 2 972 | 10 | 751 | |
| Чтение | 474 | 59 | 111 | |
| Чтение | 20 | 4 | ||
| Чтение | 85 | 69 | ||
| Чтение | 971 | 23 | 200 | |
| Чтение | 1 599 | 11 | 1 400 | |
| Чтение | 477 | 1 | 70 | |
| Чтение, Запись/Создание | 1 145 | 4 | 187 | |
| Запись/Создание | 31 | 48 | 22 | |
| Запись/Создание | 23 | 26 | 7 | |
| Запись/Создание | 457 | 7 | 174 |
Читать это руководство, не прорабатывая приведённые в нём примеры, бессмысленно. Поэтому, вооружимся и воспользуемся менеджером пакетов или pip3 для установки PyPDF2 и PyMuPDF. Наберём в командной строке (Windows):
pip3 install pypdf2 pip3 install pymupdf
Для того, что бы не запутаться создадим папочку для своего проекта. Как видите местом для неё выбрана папка «Документы» стандартной установки Windows.Вот так это выглядит в Windows
Папки и будем использовать для записи результатов работы своих программ, а в папке храним исходные PDF‑файлы, сами скрипты будем хранить в корне. Кстати, все примеры этой серии статей о работе с PDF‑файлами есть на , откуда их можно забрать и использовать в качестве «кирпича» для своих упражнений