

9. iCloud Drive
iCloud Drive — облачное хранилище данных от Apple. Если у вас есть устройство компании Apple, то у вас iCloud Drive уже будет установлен на устройстве. Вы просто должны настроить учетную запись iCloud. Тем не менее, многие люди не знают, что вы можете использовать iCloud Drive с ПК. Для безопасности данных iCloud Drive шифрует данные с помощью 128-битного AES шифрования. Он также использует 128-битное SSL-шифрование для передачи.
| Обьем | Месячная плата |
|---|---|
| 5 Гб | При регистрации, бесплатно |
| 50 Гб | 59 pублей |
| 200 Гб | 149 рублей |
| 1 Тб | 599 pублей |
| 2 Тб | 1490 pублей |
Недостатки: а) Скорость загрузки была очень медленной на некоторых тестах. б) Есть вопросы к безопасности: вы не получите ключ опции частного шифрования, что означает, что служба хранит ключи шифрования на серверах и может получить доступ к файлам без вашего согласия, если вы не используете приложение шифрования.
Сайт iCloud Drive: https://support.apple.com/en-us/HT201318
Дедупликация и компрессия
Дедупликация позволяет сократить время выполнения сжатия данных используя последовательную обработку данных дедупликацией, сокращая количество избыточных данных, и производя компрессию над уже дедуплицированными данными. При компрессии в общем виде представляет из себя изменение кодирования внутри блоков данных определенной длины. При сокращении количества блоков (в случае первоначальной обработки данных дедупликацией) время потраченное на компрессию будет меньше на время обработки для сокращенных блоков, а общий коэффициент сокращения объема данных будет так же меньше, чем при использовании одной компрессии, за счет сокращения количества сжатых объектов на выходе. Оценить параметры по времени можно зная среднюю скорость работы системы компрессии с определенным алгоритмом на целевой системе, среднюю скорость дедупликации данных, оценочный коэффициент дедупликации используемого для сокращения набора данных.
Применение последовательности из дедупликации и сжатия данных реализовано по умолчанию в продуктах Quantum DXI, В качестве примера на рисунке приведено изображение из управляющего интерфейса продукта Quantum DXiV1000 использующегося в качестве системы хранения резервных данных 4 баз данных MS SQL и дифференциальных резервных копий 4 однородных систем на платформе Microsoft Windows Server 2008R2 и одной системы на платформе Linux (дистрибутив openSuse 12.3).
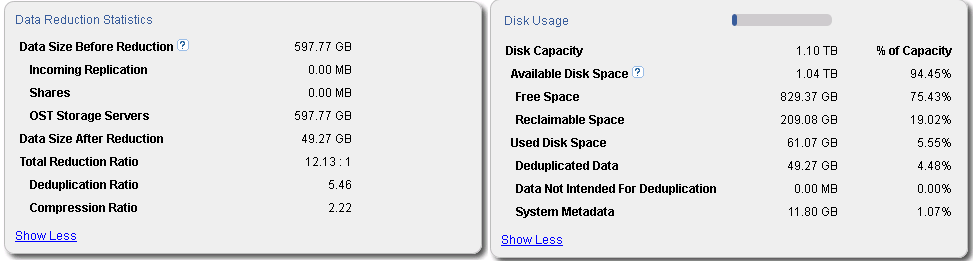
Как видно из информации из управляющего интерфейса, общее сокращение объема после обработки сокращено в 12 раз (Total Reduction Ratio в блоке Data Reduction Statistics), при этом сокращение объема более чем в 5 раз приходится именно на обработку дедупликацией (Deduplication Ratio в блоке Data Reduction Statistics), с последующем сокращением дедуплицированных данных алгоритмом компрессии в более 2 раз(Compression Ratio) в блоке Data Reduction Statistics. Помимо самих данных требуется хранить метаданные, обеспечивая целостность данных, которые на данном наборе хранения занимают 11,8 ГБ (System Metadata в блоке Disk Usage), большей частью которых являются метаданные используемые при дедупликации данных.
Суммируя объем обработанных данных с объемом метаданных общий объем необходимый для хранения резервных копий данных сокращается в 10 раз, что является наглядным показателем эффективности применения технологии дедупликации данных.
Яндекс.Диск
Яндекс тоже готов предоставить безлимитное и бесплатное хранилище для ваших фотографий.
Но (всегда есть «но») безлимит доступен только тогда, когда вы загружаете фотографии непосредственно с вашего смартфона. Во всех остальных случаях придется заплатить.
Подписка на Яндекс.Диск на 100 Гбайт обойдется дешевле, чем у Google – 80 рублей в месяц или 800 рублей в год, а за 1 Тбайт данных придется отдать 200 рублей в месяц или 2000 рублей в год.
Подписчикам Яндекс.Плюс доступны дополнительные бонусы. Во-первых, +10 Гбайт к уже существующему хранилищу Яндекс.Диска и 30% скидка на покупку места. Подписка на Яндекс.Плюс стоит 169 рублей в месяц и включает в себя безлимитный доступ к музыке, фильмам и сериалам на «Кинопоиске», а также 10% скидку на Яндекс.Такси.
В целом, Яндекс достаточно неплохой вариант для хранения фотографии с учетом цены, особенно если вы фотографируете только на смартфон.
Лучшее в облачном хранилище Яндекса:
- безлимитное хранение фотографий со смартфона;
- Возможность сэкономить, если вы пользуетесь другими сервисами или устройствами «Яндекса».
SDFS — файловая система для виртуальных окружений
Модель облачных вычислений приобретает все большую популярность. Для многих компаний (и даже частных лиц) проще и выгоднее арендовать на время уже готовые к работе выделенные виртуальные серверы, чем покупать дорогостоящее серверное оборудование и оплачивать его поддержку. Виртуальные серверы удобны, надежны, их легко восстановить после сбоев. Однако провайдеру услуг облачных вычислений их содержание обходится в кругленькую сумму, что сказывается на стоимости аренды, и, следовательно, на популярности среди клиентов. В среде провайдеров постоянно идет поиск способов удешевления содержания виртуальных машин и всей инфраструктуры в целом. Один из способов сделать это заключается в использовании технологии дедупликации данных, которая позволяет сэкономить существенные средства на объемах дискового хранилища.
Дедупликация данных представляет собой процесс исключения избыточности данных путем удаления лишних копий информации и сохранения на их месте ссылок на единственный экземпляр
Чтобы понять, почем у это так важно, и сколько дискового пространства можно сэкономить, представь себе следующую картину: ты занимаешься предоставлением услуг типа «виртуальный сервер в аренду», и для любого обратившегося к тебе клиента создаешь виртуальный сервер на основе Red Hat Enterprise Linux 5. Дела идут хорошо, поток клиентов растет, и вскоре их количество приближается к отметке 1000
Ты имеешь хорошую прибыль, но большая ее часть уходит на покупку нового железа.
Если представить, что каждому клиенту ты выделяешь 10 Гб дискового пространства, то для обслуживания 1000 клиентов тебе понадобится примерно 10 Тб дискового пространства, а это около 20 жестких дисков по 500 Гб каждый. При этом как минимум четыре из них используются для хранения одних и тех же данных, ведь базовая инсталляция ОС занимает около 2 Гб, а все эти клиенты используют одну ОС. Сложив, получаем 2 Тб копий копий копий базовой инсталляции Red Hat Enterprise Linux 5. Применив дедупликацию, ты смог бы избавиться от всех этих копий, освободив солидный участок пространства, которое заняли бы еще 200 клиентов!
Поддержка дедупликации данных существует в некоторых решениях NAS и коммерческих программных продуктах. Она была добавлена в файловую систему ZFS в ноябре 2009 года, а совсем недавно была выпущена дедуплицирующая распределенная файловая система SDFS, разработанная в рамках открытого проекта Opendedup (www.opendedup.org). Несмотря на название, SDFS не является файловой системой в прямом смысле слова. Это прослойка, написанная на языке Java и реализованная с использованием механизма для создания файловых систем пространства пользователя fuse (fuse.sf.net). SDFS состоит из следующих компонентов:
- Fuse Based File System. Файловая система уровня пользователя, предоставляющая доступ к файлам и каталогам.
- Dedup File Engine. Сервис на стороне клиента, который принимает все запросы на доступ к файлам от файловой системы и отвечает за хранение метаданных и карты дубликатов, связанных с файлами и каталогами.
- Deduplication Storage Engine. Серверная сторона, движок дедупликации. Отвечает за хранение, извлечение и удаление повторяющихся данных. Для хранения данных использует низлежащую файловую систему или хранилище Amazon S3, индексируя блоки с помощью хэш-таблицы.
На всех машинах, которые должны участвовать в хранении данных, запускается движок дедупликации. На клиентских машинах, использующих хранилище данных, запускается сервис Dedup File Engine, который подключается к доступным движкам дедупликации и получает доступ к хранилищу. Для общения с Dedup File Engine файловая система (Fuse Based File System) использует механизм JNI (Java Native Interface).
Кроме стандартной файловой системы для хранения данных может использоваться хранилище Amazon S3. Общий размер ФС способен достигать 8 Пб, максимальный размер одного файла — 250 Гб, файловая система может быть «размазана» по 256 различным хранилищам, обслуживаемым Deduplication Storage Engine. Выявление и устранение дубликатов данных происходит на уровне блоков размером 4 Кб. Файловая система способна производить дедупликацию на лету (во время записи новых данных) или же запускаться в промежутках наименьшей активности операций ввода-вывода как фоновый процесс. Среди других особенностей SDFS можно отметить поддержку снапшотов на уровне файлов и каталогов, поддержку экспорта с помощью протоколов NFS и CIFS и достаточно высокую производительность.
Включение и настройка дедупликации
После установки компонентов вам необходимо включить дедупликацию для определенного тома (или нескольких томов). Это можно сделать двумя способами: с помощью графического интерфейса или с помощью PowerShell.
Чтобы настроить компонент из GUI, откройте Server Manager, перейдите в File and storage services -> Volumes, выберите нужный том, щелкните правой кнопкой мыши и в меню выберите «Configure Data Deduplication».
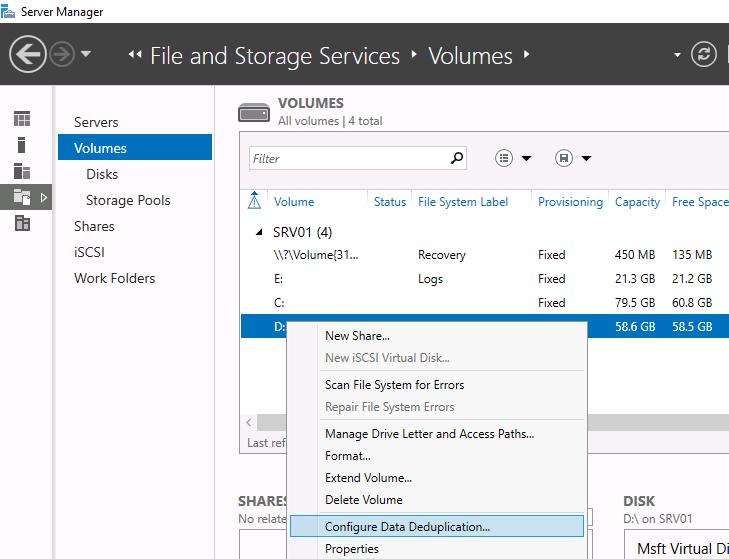
Затем выберите нужный тип дедупликации (например, General puprose file server) и нажмите «Применить». Кроме того, вы можете указать типы файлов, которые не должны подвергаться дедупликации, а также создать исключения для определенных каталогов (каталоги с мультимедиа файйлами, базами и т.д.).
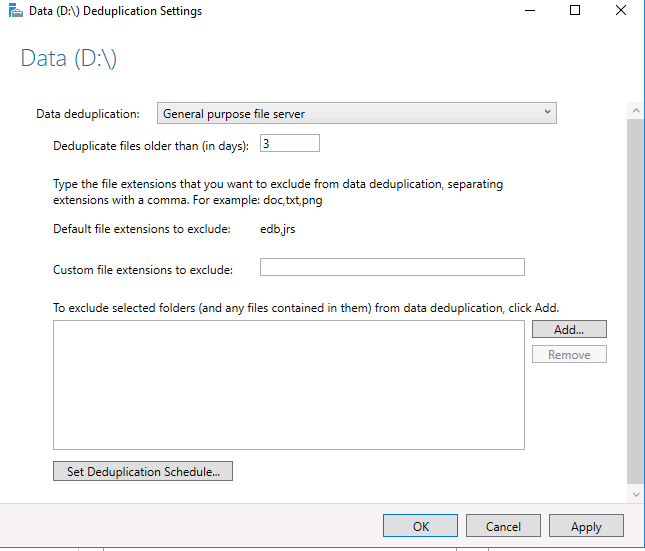
Затем вам необходимо настроить расписание, по которому будет работать задание дедупликации. Нажмите кнопку Set Deduplication Schedule.
По умолчанию включена фоновая оптимизация (background optimization), и вы можете настроить две дополнительные задачи принудительной оптимизации (throughput optimization). Здесь есть несколько настроек — вы можете выбрать дни недели, время начала и продолжительность работы.
Еще больше возможностей для настройки дедупликации предоставляет PowerShell. Чтобы включить дедупликацию, используйте следующую команду:
Список текущих заданий дедупликации:
Как вы видите, в дополнении к фоновой задачи оптимизации есть задача приоритетной оптимизации (PriorityOptimization), а также задания по сбору мусора (GarbageCollection) и очистке (Scrubbing). Все эти задачи нельзя увидеть в графическом интерфейсе.
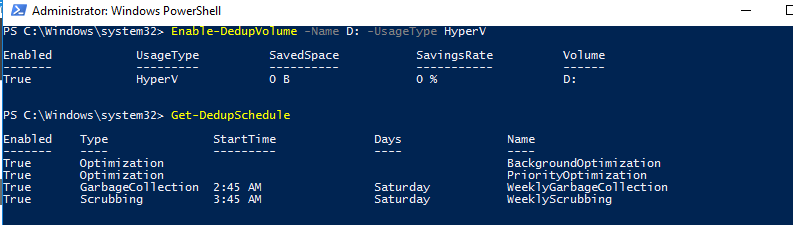
PowerShell позволяет вам точно настроить параметры заданий дедупликации. Например, создадим такую задачу оптимизации: задача должна запускаться в 9 утра с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, используя не более 20% ОЗУ и 20% CPU:
Отключим приоритетную оптимизацию:
Подготовка
Важно определить, в каком аккаунте находятся основные данные пользователя, например электронные письма, мероприятия из календаря, объекты Google Диска и информация для доступа к сторонним приложениям. С ним пользователь будет работать после объединения
В этом сценарии предполагается, что в течение последних трех месяцев пользователь работал с одним аккаунтом. Если были задействованы оба аккаунта для разных целей и в обоих есть новые данные, этот метод может не подойти или подойти только частично.


![Облачный менеджер дисков cloudbuckit [обзор]](https://befam.ru/wp-content/uploads/5/9/9/5996241fdf653038af0ebe17b38a98c6.jpeg)




| Свернуть все и перейти к началу
Как сопоставить исходный и целевой аккаунты пользователя
Создайте сопоставление между исходным и целевым аккаунтами пользователя, например:
- polzovatelA@example.com > a.polzovatel@solarmora.com
- polzovatelB@example.com > polzovatelB@solarmora.com
Как найти основной аккаунт пользователя
Определите, какой аккаунт является для пользователя основным. Примеры того, как это можно сделать, приведены ниже.
- Проанализируйте суть слияния и поглощения. Во многих случаях дублирующиеся аккаунты были предоставлены для определенной цели и использовались только от случая к случаю.
- Спросите у пользователя.
- С помощью отчета об аккаунтах пользователей в Google Workspace изучите использование разных приложений, в том числе посмотрите сведения о:
- статусах аккаунтов пользователя;
- хранилище Gmail;
- пространстве на Диске;
- общем объеме хранилища;
- общем количестве писем;
- отредактированных файлах;
- просмотренных файлах;
- времени последнего использования Диска.
- С помощью поиска в журнале электронной почты Google Workspace проанализируйте использование электронной почты за последние 30 дней:
- Сообщения, с момента отправки которых прошло не более семи дней и не менее часа, либо письма за указанный диапазон дат (за последние 30 дней).Примечание. Для сообщений, отправленных или полученных более 30 дней назад, в результатах поиска указаны только сведения о действиях после доставки.
- Сведения о действиях с письмом после его доставки хранятся бессрочно.
- Сообщения, адресатами или отправителями которых являются пользователи Google Workspace в ваших доменах.
- Сообщения, отправленные в группу Google и по спискам рассылки, в которые входят пользователи Google Workspace вашей организации.
- В организациях, использующих версию Enterprise, можно посмотреть отчет о доставке сообщений в центре безопасности.
Шаг 1. Определите, можно ли дедуплицировать ваши данные
Определите, выиграют ли ваши данные от экономии места при дедупликации с помощью инструмента отладки ZFS, zdb. Если ваши данные не поддерживают дедупликацию, нет смысла включать файлы dedup.
Дедупликация выполняется с использованием контрольных сумм. Если блок имеет ту же контрольную сумму, что и блок, который уже записан в пул, он считается дубликатом и, таким образом, на диск записывается только указатель на уже сохраненный блок.
Таким образом, процесс дедупликации данных, которые не могут быть дедуплицированы, впустую будут тратить ресурсы ЦП. Дедупликация ZFS является внутренней. Это означает, что дедупликация происходит при записи данных на диск и влияет как на ресурсы ЦП, так и на ресурсы памяти.
Посмотрим какие есть пулы. И в примере ниже нам интересно рассматривать rpool.
$ zpool list NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT bpool 1.88G 241M 1.64G - - 0% 12% 1.00x ONLINE - rpool 232G 121G 111G - - 2% 51% 1.00x ONLINE -
Теперь собираем информацию о характере данных. Например, если предполагаемый коэффициент дедупликации больше 2, вы можете увидеть экономию места при дедупликации. В примере, показанном в листинге ниже, коэффициент дедупликации меньше 2, поэтому включать dedup не рекомендуется.
$ zdb -S rpool
Simulated DDT histogram:
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE
------ ------ ----- ----- ----- ------ ----- ----- -----
1 1.17M 129G 104G 105G 1.17M 129G 104G 105G
2 73.9K 6.49G 5.45G 5.50G 153K 13.5G 11.3G 11.4G
4 7.42K 857M 711M 713M 33.0K 3.70G 2.97G 2.98G
8 1019 87.2M 43.8M 44.7M 10.9K 993M 502M 511M
16 151 9.06M 5.50M 5.70M 3.11K 186M 113M 118M
32 109 1.50M 1.21M 1.29M 5.16K 68.6M 55.5M 59.3M
64 14 1.16M 1.03M 1.04M 1.26K 113M 102M 103M
128 4 258K 10K 16K 812 58.6M 2.19M 3.17M
256 1 128K 4K 4K 445 55.6M 1.74M 1.74M
Total 1.25M 136G 111G 111G 1.37M 147G 120G 120G
dedup = 1.08, compress = 1.23, copies = 1.00, dedup * compress / copies = 1.33
Стратегия 5: Мониторинг показателей качества данных
Постоянные усилия по поддержанию чистоты и дедупликации ваших данных — лучший способ реализовать вашу стратегию дедупликации данных. Здесь может быть очень полезен инструмент, который предлагает функции профилирования данных и управления качеством. Маркетологам необходимо следить за тем, насколько точными, достоверными, полными, уникальными и последовательными являются данные, которые используются для маркетинговых операций.
Поскольку организации продолжают добавлять приложения для обработки данных в свои бизнес-процессы, у каждого маркетолога возникла необходимость иметь стратегии дедупликации данных. Такие инициативы, как использование инструментов дедупликации данных и разработка более эффективных рабочих процессов проверки для создания и обновления записей данных, — вот некоторые важные стратегии, которые могут обеспечить надежное качество данных в вашей организации.
Baidu Cloud
Завершает топ-парад облачных хранилищ китайский сервис Baidu Cloud. Как видно по скриншоту, для нас с вами он явно не адаптирован. Зачем же он тогда нужен, если существуют более привычные русскоязычному человеку отечественные, европейские и американские аналоги? Дело в том, что Baidu предоставляет пользователям целый терабайт бесплатного дискового пространства. Ради этого и стоит преодолеть трудности перевода и другие препятствия.
Регистрация на Baidu Cloud значительно более трудоемка, чем у конкурентов. Она требует подтверждения кодом, присланным по SMS, а SMS с китайского сервера на российские, белорусские и украинские номера не приходит. Нашим согражданам приходится выкручиваться с помощью аренды виртуального номера телефона, но это еще не всё. Вторая сложность заключается в том, что аккаунт нельзя зарегистрировать на некоторые адреса электронной почты. В частности, на сервисах gmail (Google заблокирован в Китае), fastmail и Яндекс. И третья сложность — это необходимость установки мобильного приложения Baidu Cloud на телефон или планшет, так как именно за это и дается 1 Тб (при регистрации на компьютере вы получите всего 5 Гб). А оно, как вы понимаете, полностью на китайском.
Не испугались? Дерзайте — и будете вознаграждены. Информация, как своими руками создать аккаунт на Baidu, есть в Интернете.
Image Credit: Blue Coat Photos on Flickr
Отключение дедупликации в пулах / файловых системах ZFS:
После включения дедупликации в пуле / файловой системе ZFS дедуплицированные данные останутся дедуплицированными. Вы не сможете избавиться от дедуплицированных данных, даже если отключите дедупликацию в пуле / файловой системе ZFS.
Но есть простой способ удалить дедупликацию из пула / файловой системы ZFS:
i) Скопируйте все данные из пула / файловой системы ZFS в другое место.
ii) Удалите все данные из пула / файловой системы ZFS.
iii) Отключите дедупликацию в вашем пуле / файловой системе ZFS.
iv) Переместите данные обратно в пул / файловую систему ZFS.
Вы можете отключить дедупликацию в своем пуле ZFS бассейн1 с помощью следующей команды:
$ судо zfs задаватьдедупликация= за пределами пула1

Вы можете отключить дедупликацию в файловой системе ZFS fs1 (создан в пуле бассейн1) с помощью следующей команды:
$ судо zfs задаватьдедупликация= за пределами пула1fs1
После удаления всех дедуплицированных файлов и отключения дедупликации таблица дедупликации (DDT) должна быть пустой, как показано на снимке экрана ниже. Таким образом вы проверяете, что в вашем пуле / файловой системе ZFS не происходит дедупликации.
$ судо статус zpool -D бассейн1
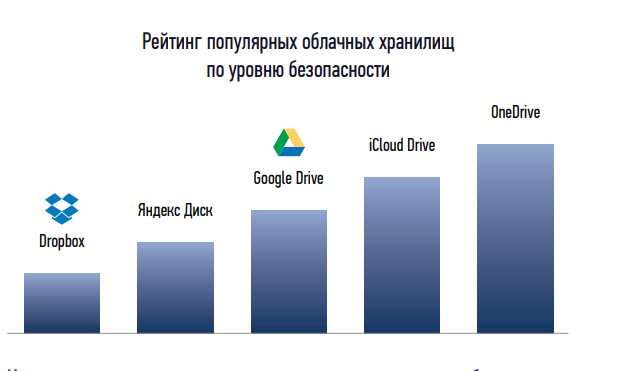
Какое облачное хранилище лучше?
Однозначно ответить на этот вопрос не получится. Наиболее универсальным и заточенным под хранение фотографий на сегодняшний день является Google Фото. У него удобная загрузка, есть возможности для обработки и сортировки файлов.
Но и у других облачных хранилищ есть свои сильные стороны. iCloud или Samsung Cloud хорошо заточены под конкретные устройства от компании Apple и Samsung.
Яндекс Диск, облако Mail.ru хороши, когда требуется хранилище для хранения любых данных, а не только фотографий.
Microsoft One Drive и Acronis отлично подойдут, если вы используете другие решения этих производителей.
Ну а Mega — это много гигабайт фактически бесплатно.
Apple iCloud
Компания Apple в 2019 году не изменяет своим традициям и бесплатно предоставляет в облаке всего 5 Гбайт данных. Стоит понимать, что бесплатные 5 Гбайт не только для фотографий, но и для ваших резервных копий iOS устройств. А если «яблочных» девайсов у вас много, то это очень мало. Поэтому пользователи устройств из Купертино вынуждены докупать место в облачном хранилище.








Увеличение объема до 50 Гбайт обойдется вам в 59 рублей в месяц, до 200 Гбайт – в 149 рублей в месяц, а за 2 Тбайт данных в облачном хранилище с вас попросят уже 599 рублей в месяц или 7188 рублей в год.
Но если вы не пользуйтесь никакими iOS устройствами, то облако Apple будет не самым удобным вариантом. Все фотографии придется просматривать только через Web-версию. Никаких приложений для Android-устройств у «яблочников» нет. Для Windows же вы можете скачать специальное приложение – iCloud для Windows.
Microsoft One Drive
Облачное хранилище от Microsoft называется Microsoft One Drive. Базовый бесплатный объем, как и у Apple, составляет всего 5 Гбайт. Для фотографий и данных это очень мало.
Однако если вы пользуетесь Office 365 (подписка на приложения Microsoft Office), то редмондцы предоставляют вам 1 Тбайт данных и вы можете использовать его по своему усмотрению. А если у вас семейная подписка на Office 365, то вместо 1 Тбайт данных вы получаете уже целых 6 Тбайт, но использовать их одному не выйдет – каждому из участников семейного доступа (их может быть до 6 человек) предоставляется ровно по 1 Тбайт.
Как мы уже упоминали раньше, купить подписку на Office 365 на официальном сайте компании сейчас нельзя и приобрести ключ можно только у одного из магазинов-партнеров Microsoft. Например, в одном из магазинов лицензионного софта – AllSoft.ru – Office 365 персональный можно купить за 2297 рублей в год, а Office 365 домашний – за 2815 рублей в год.
Лучшее в облачном хранилище Microsoft One Drive:
- интеграция с Office 365;
- богатые возможности для совместной работы;
- большой объем, особенно при использовании семейной подписки.
CEPH — распределенная файловая система
Ситуация с распределенными файловыми системами в мире Open Source далека от идеала. Существует множество готовых для промышленной эксплуатации проектов, однако ни один из них не может похвастаться хорошим сочетанием важных для распределенных ФС характеристик. Одни обладают высокой надежностью, но проваливают тесты на производительность, другие вырываются в лидеры по скорости доступа, но обеспечивают не самый лучший показатель надежности и расширяемости, третьи могут расти почти до бесконечности, но издевательски медленны. Не удивительно, что исследовательские работы в этой области ведутся непрерывно, и почти каждый год мы становимся свидетелями рождения новой распределенной ФС, которая претендует на звание идеала. Это произошло и с файловой системой Ceph, которая оказалась настолько успешной, что код ее клиента было решено включить в Linux-ядро версии 2.6.34.
Ceph (http://ceph.newdream.net) имеет достаточно долгую историю развития; впервые ее архитектура была описана автором Сэйджем Вилом в его дипломной работе в 2006 году. К ноябрю 2007 года он представил стабильную версию, реализованную с использованием fuse, и начал работать над реализацией модуля для ядра Linux. Сегодня Ceph уже достаточно стабильна для повседневного использования.
Среди главных плюсов Ceph автор отмечает следующие:
- Совместимость со стандартом POSIX;
- Прозрачное масштабирование от десятка до тысячи узлов;
- Общий объем хранилища (может составлять сотни петабайт);
- Высокие показатели доступности и надежности;
- N-way репликация всех данных на множество узлов;
- Автоматическая ребалансировка данных в случае добавления/удаления узла для более эффективного использования ресурсов;
- Простота развертывания (большинство компонентов файловой системы реализованы в виде демонов пространства пользователя);
- Наличие fuse-клиента;
- Наличие клиента для ядра Linux.
В отличие от кластерных файловых систем, таких как GFS, OCFS2 и GPFS, которые опираются на симметричный доступ всех клиентов к общим блочным устройствам, Ceph разделяет управление данными и метаданными путем использования независимых кластеров (примерно так же, как это делает Lustre). Однако, в отличие от последней, узлы, управляющие метаданными и хранилищем, не требуют какой бы то ни было поддержки со стороны ядра; весь код работает в пространстве пользователя. Для хранения объектов данных узлы могут использовать блочные устройства, образы или низлежащую файловую систему. Когда один из узлов дает сбой, данные реплицируются самими узлами, благодаря чему достигается высокий уровень эффективности и масштабируемости.
Серверы, отвечающие за хранение метаданных (metadata server), представляют собой нечто вроде большого согласованного распределенного кэша на вершине кластера-хранилища, который динамически перераспределяет метаданные в ответ на изменение нагрузки и легко переносит выход узлов из строя. Metadata server использует особый подход для хранения метаданных, который позволяет достичь высоких показателей производительности. Например, inode-запись, имеющая только одну жесткую ссылку, помещается прямо в каталоговую запись.
Поэтому каталог вместе со всеми адресуемыми им inode’ами может быть загружен в кэш с помощью одной операции ввода-вывода. Содержимое очень больших каталогов фрагментируется и отдается на управление независимым metadata-серверам, благодаря чему операцию доступа к каталогу можно легко распараллелить.
По словам автора Ceph, наиболее важное достоинство его ФС заключает ся в полностью автоматизированном механизме ребалансировки и миграции при масштабировании от небольшого кластера, состоящего из нескольких узлов, до кластера корпоративных масштабов, в котором участвуют несколько сотен узлов. Этот процесс требует минимального вмешательства администратора, новые узлы могут быть подключены к кластеру, и все будет «просто работать»
Установка дедупликации данных
Важно!
Обновление KB4025334 содержит накопительный пакет исправлений, в том числе обеспечивающих надежность системы. Мы настоятельно рекомендуем установить его при использовании дедупликации данных в Windows Server 2016.
Установка дедупликации данных с помощью диспетчера сервера
- В мастере добавления ролей и компонентов выберите Роли сервера, а затем Дедупликация данных.
- Нажимайте кнопку Далее, пока не будет активирована кнопка Установить, а затем щелкните Установить.
Установка дедупликации данных с помощью PowerShell
Чтобы установить дедупликацию данных, выполните следующую команду PowerShell от имени администратора:
Чтобы установить дедупликацию данных, выполните приведенные далее действия.
-
С сервера, на котором выполняется Windows Server 2016 или более поздней версии, или с компьютера с Windows с установленными средствами удаленного администрирования сервера (RSAT), установите дедупликацию данных с явной ссылкой на имя сервера (замените MyServer реальным именем экземпляра сервера):
либо
-
Удаленно подключитесь к экземпляру сервера с помощью удаленного взаимодействия PowerShell и установите дедупликацию данных с помощью DISM:
Что представляют собой облачные хранилища с точки зрения пользователя и как они работают
Если взглянуть глазами неискушенного юзера, облачное хранилище — это обычное приложение. Оно только и делает, что создает на компьютере папку под собственным именем. Но не простую. Всё, что вы в нее помещаете, одновременно копируется на тот самый облачный Интернет-сервер и становится доступным с других устройств. Размер этой папки ограничен и может увеличиваться в пределах выделенного вам дискового пространства (в среднем от 2 Гб).
Если приложение облачного хранилища запущено и компьютер (мобильный гаджет) подключен к глобальной сети, данные на жестком диске и в облаке синхронизируются в реальном времени. При автономной работе, а также, когда приложение не работает, все изменения сохраняются только в локальной папке. При подключении машины к Интернету доступ к хранилищу становится возможен в том числе через браузер.
Файлы и папки, загруженные в облако, являются полноценными веб-объектами, такими же, как любой контент интернет-сайтов и ftp-хранилищ. Вы можете ссылаться на них и делиться ссылками с другими людьми, даже с теми, кто не пользуется этим сервисом. Но скачать или увидеть объект из вашего хранилища сможет только тот, кому вы сами это разрешили. В облаке ваши данные скрыты от посторонних глаз и надежно защищены паролем.
Основная масса облачных сервисов имеет дополнительный функционал — средство просмотра файлов, встроенные редакторы документов, инструменты создания скриншотов и т. п. Это плюс объем предоставляемого пространства и создает главные отличия между ними.
Поиск одинаковых файлов на компьютере: сканирование и фильтрация
Всем привет! Сегодня в статье мы поговорим про поиск дубликатов файлов на нашем компьютере и их последующее удаление. Как бы вы аккуратно не пользовались системой и сторонними файлами и папками, в любом случае пользователь или некоторые программы, накапливают уйму гигабайтов дублированных файлов и папок. В таком случае места на дисках становится меньше. Сильнее всего страдает системный том «C:».
Для чего некоторые программы создают дубли файлов? – на самом деле «на всякий случай», а вдруг с основным файлом что-то случится. Понятное дело, что создание таких файлов происходит не всегда, а только в моменты запуска важных функций. Очень часто и сам пользователь создает тонны дублей, даже не замечая этого. И как итог – места на дисках становится в разы меньше.
Прежде чем вы приступите к прочтению этой статьи, я вам настоятельно рекомендую перед этим ознакомиться вот с этой инструкцией:
И вот только после этого читаем то, что я описал ниже. Инструкция выше поможет вам освободить куда больше лишней информации, а места на дисках станет больше. И еще один важный момент – поиск одинаковых файлов на компьютере стоит включать только в своих разделах. Не стоит его запускать на системном диске «C:», так как есть риск удаления важных файлов. На системном диске, как я и говорил ранее, хранится очень много специально созданных дубликатов или, точнее сказать, резервных копий важных системных файлов.
Поиск дубликатов файлов с помощью Total Commander Поиск дубликатов
Завершение поиска — определение правильно объекта и удаление дублей
После завершения поиска программа выдает список найденных объектов по заданным ранее параметрам поиска (Рис. 23).
Рис. 23 Отображение списка найденных объектов при поиске дублей
Для изменения «объекта – оригинала», который останется после склейки – сниманием галочки, затем отметку «стрелкой, как оригинал», и проставляем на нужный обьект, который будет «оригиналом» после (Рис.25).
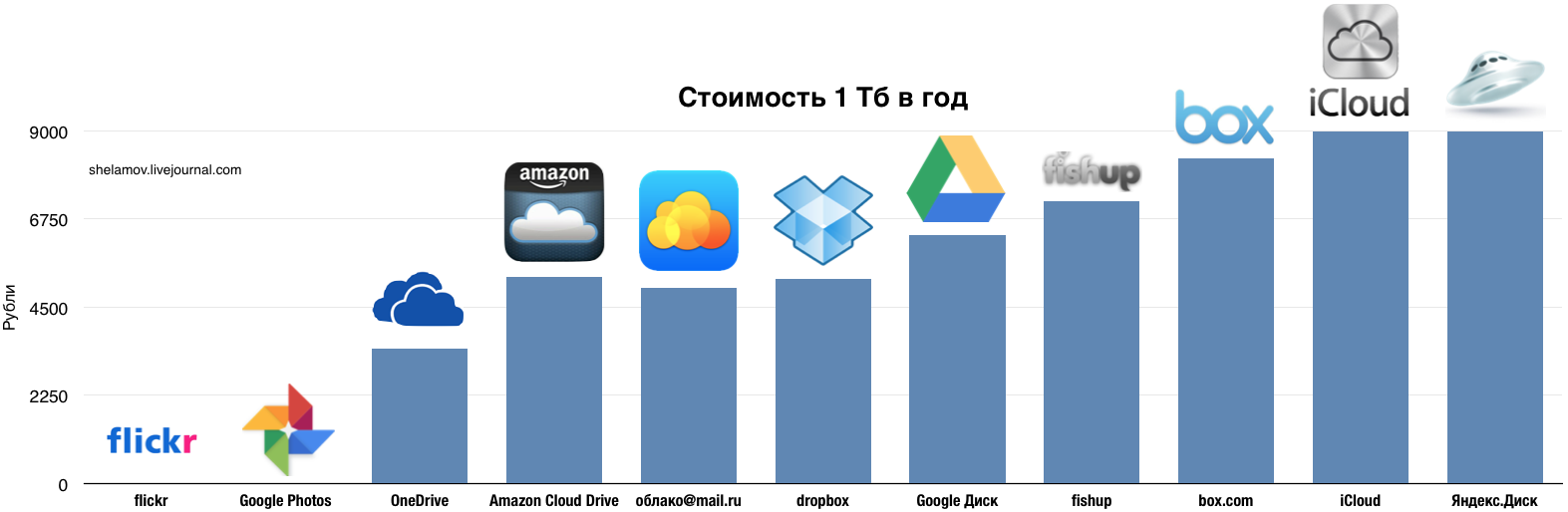






Рис.25 Изменения объекта, на который переходят найденные дубли
Если же каталог имеет большое количество объектов, которые совпадают по заданным настройкам отбора, в список найденных объектах могут попасть объекты, которые не должны быть склеены в таком случае снимаем отметку «Галочки»с объектов которые не будут участвовать при склейке (Рис.26).
Рис.26 Отображения объектов для склейки
Проверить список найденных задулированых объектов можно открытием карты сразу из списка и просмотреть ее. Так же в правом углу выводится список документов, где ранее участвовала карта (Рис.27).
Рис.27 Просмотр списка документов и карты дубля
После проверки правильности настройки объектов, которые будут удалены и, при необходимости, заменены на объект – оригинал и отметки объектов, на которые не будут участвовать в склейки, запускаем удаление дублей (Рис.28).
Рис.28 Удаление дублей
При успешном правильном объединении программа выдаст соответствующее сообщение, что дубли найдены и объединенный (Рис.29).
Рис.29 Завершение объединения дублей
Просмотров: 1 366